The string2string library is an open-source tool that has a full set of efficient methods for string-to-string problems.1 String pairwise alignment, distance measurement, lexical and semantic search, and similarity analysis are all covered in this library. Additionally, a variety of useful visualization tools and metrics that make it simpler to comprehend and evaluate the findings of these approaches are also included.
The library has well-known algorithms like the Smith-Waterman, Hirschberg, Wagner-Fisher, BARTScore, BERTScore, Knuth-Morris-Pratt, and Faiss search. It can be used for many jobs and problems in natural-language processing, bioinformatics, and computer social studies [1].
The Stanford NLP group, which is part of the Stanford AI Lab, has developed the library and introduced it in [1]. The library’s GitHub repository has several tutorials that you may find useful.
Note
A string is a sequence of characters (letters, numbers, and symbols) that stands for a piece of data or text. From everyday phrases to DNA sequences, and even computer programs, strings may be used to represent just about everything [1].
Installation
You can install the library via pip by running pip install string2string.
Pairwise Alignment
String pairwise alignment is a method used in NLP and other disciplines to compare two strings, or sequences of characters, by highlighting their shared and unique characteristics. The two strings are aligned, and a similarity score is calculated based on the number of shared characters, as well as the number of shared gaps and mismatches. This procedure is useful for locating sequences of characters that share similarities and calculating the “distance” between two sets of strings. Spell checking, text analysis, and bioinformatics sequence comparison (e.g., DNA sequence alignment) are just some of the many uses for it.
Currently, the string2string package provides the following alignment techniques:
Needleman-Wunsch for global alignment
Smith-Waterman for local alignment
Hirchberg’s algorithm for linear space global alignment
Longest common subsequence
Longest common substring
Dynamic time warping (DTW) for time series alignment
In this post, we’ll look at two examples: one for global alignment and one for time series alignment.
Needleman-Wunsch Algorithm for Global Alignment
The Needleman-Wunsch algorithm is a type of dynamic programming algorithm that is often used in bioinformatics to match two DNA or protein sequences, globally.
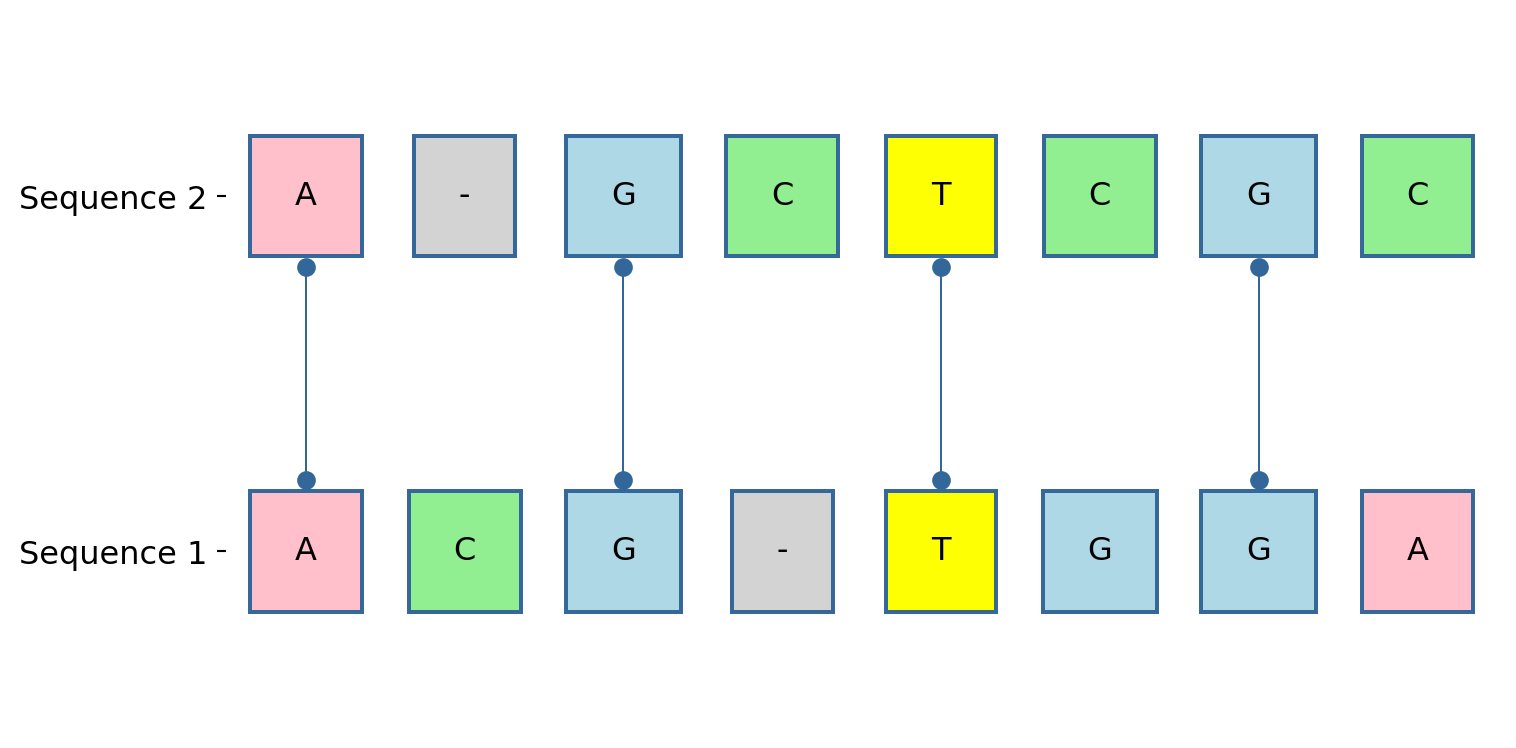
from string2string.alignment import NeedlemanWunschnw = NeedlemanWunsch()# Define two sequencess1 ='ACGTGGA's2 ='AGCTCGC'aligned_s1, aligned_s2, score_matrix = nw.get_alignment(s1, s2, return_score_matrix=True)print(f'The alignment between "{s1}" and "{s2}":')nw.print_alignment(aligned_s1, aligned_s2)
The alignment between "ACGTGGA" and "AGCTCGC":
A | C | G | - | T | G | G | A
A | - | G | C | T | C | G | C
For a more informative comparison, we can use plot_pairwise_alignment() function in the library.
Figure 1: Global alignment between ACGTGGA and AGCTCGC
Dynamic Time Warping
DTW is a useful tool to compare two time series that might differ in speed, duration, or both. It discovers the path across these distances that minimizes the total difference between the sequences by calculating the “distance” between each pair of points in the two sequences.
Let’s go over an example using the alignment module in the string2string library.
Above is an example borrowed from my previous post, An Illustrative Introduction to Dynamic Time Warping. For those looking to delve deeper into the topic, in [2], I explained the core concepts of DTW in a visual and accessible way.
Search Problems
String search is the task of finding a pattern substring within another string. The library offers two types of search algorithms: lexical search and semantic search.
Lexical Search (exact-match search)
Lexical search, in layman’s terms, is the act of searching for certain words or phrases inside a text, analogous to searching for a word or phrase in a dictionary or a book.
Instead of trying to figure out what a string of letters or words means, it just tries to match them exactly. When it comes to search engines and information retrieval, lexical search is a basic strategy to finding relevant resources based on the keywords or phrases users enter, without any attempt at comprehending the linguistic context of the words or phrases in question.
Currently, the string2string library provides the following lexical search algorithm:
Naive (brute-force) search algorithm
Rabin-Karp search algorithm
Knuth-Morris-Pratt (KMP) search algorithm (see the example below)
Boyer-Moore search algorithm
from string2string.search import KMPSearchkmp_search = KMPSearch()pattern ="Redwood tree"text ="The gentle fluttering of a Monarch butterfly, the towering majesty of a Redwood tree, and the crashing of ocean waves are all wonders of nature."idx = kmp_search.search(pattern=pattern, text=text)print(f"The starting index of pattern: {idx}")print(f'The pattern (± characters) inside the text: "{text[idx-5: idx+len(pattern)+5]}"')
The starting index of pattern: 72
The pattern (± characters) inside the text: "of a Redwood tree, and"
Semantic Search
Semantic search is a more sophisticated method of information retrieval that goes beyond simple word or phrase searches. It employs NLP (natural language processing) to decipher a user’s intent and return accurate results.
To put it another way, let’s say you’re interested in “how to grow apples.” While a lexical search may produce results including the terms “grow” and “apples,” a semantic search will recognize that you are interested in the cultivation of apple trees and deliver results accordingly. The search engine would then prioritize results that not only included the phrases it was looking for but also gave relevant information about planting, trimming, and harvesting apple trees.
Semantic Search via Faiss
Faiss (Facebook AI Similarity Search) is an efficient similarity search tool that is useful for dealing with high-dimensional data with numerical representations [3]. The string2string library has a wrapper for the FAISS library developed by Facebook (see GitHub repository.
In short, Faiss search ranks its results based on a “score,” representing the degree to which two objects are similar to one another. The score makes it possible to interpret and prioritize search results based on how close/relevant they are to the desired target.
Let’s see how the Faiss search is used in the string2string library. Here, we have a corpus2 of 11 sentences, and we will do a semantic search by querying a target sentence to see how close/relevant it is to these sentences.
corpus = {"text": ["A warm cup of tea in the morning helps me start the day right.","Staying active is important for maintaining a healthy lifestyle.","I find inspiration in trying out new activities or hobbies.","The view from my window is always a source of inspiration.","The encouragement from my loved ones keeps me going.","The novel I've picked up recently has been a page-turner.","Listening to podcasts helps me stay focused during work.","I can't wait to explore the new art gallery downtown.","Meditating in a peaceful environment brings clarity to my thoughts.","I believe empathy is a crucial quality to possess.","I like to exercise a few times a week." ]}query ="I enjoy walking early morning before I start my work."
Let’s initialize the FaissSearch object. Facebook’s BART Large model is the default model and tokenizer for the FaissSearch object.
Query: I enjoy walking early morning before I start my work.
Result 1 (score=208.49): "I find inspiration in trying out new activities or hobbies."
Result 2 (score=218.21): "I like to exercise a few times a week."
Result 3 (score=225.96): "I can't wait to explore the new art gallery downtown."
Distance
String distance is the task of quantifying the degree to which two supplied strings differ using a distance function. Currently, the string2string library offers the following distance functions:
Levenshtein edit distance, or simply the edit distance, is the minimal number of insertions, deletions, or substitutions needed to convert one string into another.
from string2string.distance import LevenshteinEditDistanceedit_dist = LevenshteinEditDistance()# Create two stringss1 ="The beautiful cherry blossoms bloom in the spring time."s2 ="The beutiful cherry blosoms bloom in the spring time."# Let's compute the edit distance between the two strings and measure the computation timeedit_dist_score = edit_dist.compute(s1, s2, method="dynamic-programming")print(f'The distance between the following two sentences is {edit_dist_score}:') #\n- "{s1}"\n- "{s2}"')print(f'"The beautiful cherry blossoms bloom in the spring time."')print(f'"The beutiful cherry blosoms bloom in the spring time."')
The distance between the following two sentences is 2.0:
"The beautiful cherry blossoms bloom in the spring time."
"The beutiful cherry blosoms bloom in the spring time."
Jaccard Index
The Jaccard index can be used to quantify the similarity between sets of words or tokens and is commonly used in tasks such as document similarity or topic modeling. For example, the Jaccard index can be used to measure the overlap between the sets of words in two different documents or to identify the most similar topics across a collection of documents.
from string2string.distance import JaccardIndex jaccard_dist = JaccardIndex()# Suppose we have two documentsdoc1 = ["red", "green", "blue", "yellow", "purple", "pink"]doc2 = ["green", "orange", "cyan", "red"]jaccard_dist_score = jaccard_dist.compute(doc1, doc2)print(f"Jaccard distance between doc1 and doc2: {jaccard_dist_score:.2f}")
Jaccard distance between doc1 and doc2: 0.75
Similarity
To put it simply, string similarity determines the degree to which two strings of text (or sequences of characters) are linked or similar to one another. Take, as an example, the following pair of sentences:
“The cat sat on the mat.”
“The cat was sitting on the rug.”
Although not identical, these statements share vocabulary and convey a connected sense. Methods based on string similarity analysis reveal and quantify the degree of similarity between such text pairings.
TipDuality
There is a duality between string similarity and distance measures, meaning that they can be used interchangeably see [1].
The similarly module of the string2string library currently offers the following algorithms:
Cosine similarity
BERTScore
BARTScore
Jaro similarity
LCSubsequence similarity
Let’s go over an example of the BERTScore similarity algorithm with the following four sentences:
The bakery sells a variety of delicious pastries and bread.
The park features a playground, walking trails, and picnic areas.
The festival showcases independent movies from around the world.
A range of tasty bread and pastries are available at the bakery.
Sentences 1 and 2 are similar semantically, as both are about bakery and pastry. Hence, we should expect a high similarity score between the two.
Let’s implement the above example in the library.
from string2string.similarity import BERTScorefrom string2string.misc import ModelEmbeddingsbert_score = BERTScore(model_name_or_path="bert-base-uncased")bart_model = ModelEmbeddings(model_name_or_path="facebook/bart-large")sentences = ["The bakery sells a variety of delicious pastries and bread.", "The park features a playground, walking trails, and picnic areas.", "The festival showcases independent movies from around the world.", "A range of tasty bread and pastries are available at the bakery.", ]embeds = [ bart_model.get_embeddings( sentence, embedding_type='mean_pooling' ) for sentence in sentences]# Define source and target sentences (to compute BERTScore for each pair)source_sentences, target_sentences = [], []for i inrange(len(sentences)):for j inrange(len(sentences)): source_sentences.append(sentences[i]) target_sentences.append(sentences[j])# You can rewrite above in a more concise way using itertools.product# from itertools import product# source_sentences, target_sentences = map(# list, zip(*product(sentences, repeat=2))# )bertscore_similarity_scores = bert_score.compute( source_sentences, target_sentences,)bertscore_precision_scores = bertscore_similarity_scores['precision'].reshape(len(sentences), len(sentences))
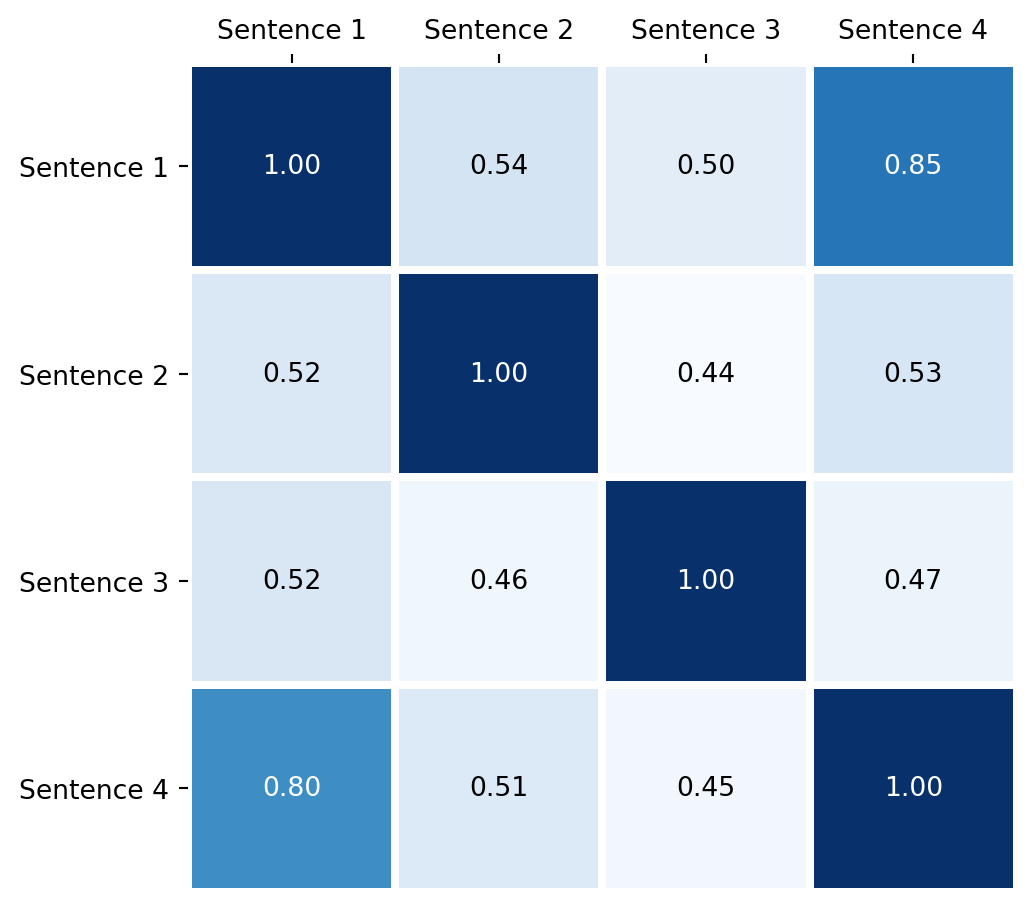
We can visualize the similarity between every pair of sentences using the plot_heatmap() function provided in the library.
from string2string.misc.plotting_functions import plot_heatmapplot_ticks = [f"Sentence {i +1}"for i inrange(len(sentences))]# We can also visualize the BERTScore similarity scores using a heatmapplot_heatmap( bertscore_precision_scores, title="", x_ticks=plot_ticks, y_ticks=plot_ticks, x_label="", y_label="", valfmt="{x:.2f}", cmap="Blues",)
Figure 2: Semantic similarity (BERTScore) between sentences
As can be seen above, sentences 1 and 4 are much more similar (using the BERTScore algorithm) as we expected.
Note
📓 You can find the Jupyter notebook for this blog post on GitHub.
Conclusion
The string2string Python library is an open-source tool that provides a full set of efficient methods for string-to-string problems. In particular, the library has four main modules that address the following tasks: 1. pairwise alignment including both global and local alignments; 2. distance measurement; 3. lexical and semantic search; and 4. similarity analysis. The library offers various algorithms in each category and provides helpful visualization tools.
Added a commented code on using product() function from itertools library.
May 15, 2023
-
Added a link to the published version of this post on Towards Data Science blog.
References
[1]
M. Suzgun, S. M. Shieber, and D. Jurafsky, “string2string: A modern python library for string-to-string algorithms,” 2023, Available: http://arxiv.org/abs/2304.14395